Le Cirque du Soleil offre Saltimbanco à Casablanca
du 6 au 13 avril au stade Mohamed V
Saltimbanco - de l'italien saltare in banco, qui signifie littéralement "sauter sur un banc" - explore l'environnement urbain et ses multiples facettes : les gens qui y vivent, leurs différences et leur ressemblances, la famille et le groupe, le grouillement de la rue et les hauteurs vertigineuses des gratte-ciel. Entre cohue et harmonie, prouesse et poésie, Saltimbanco invite à un voyage allégorique et acrobatique au cur de la cité.
Saltimbanco est un spectacle emblématique du Cirque du Soleil inspiré du métissage et de l'urbanité des grandes villes. Issus d'un univers visuel baroque, ses personnages bigarrés et cosmopolites entraînent le spectateur au milieu d'un monde fantaisiste et onirique, une ville imaginaire où diversité se conjugue avec espoir.
Quelques numéros du spectacle:
ADAGIO

Bicyclette artistique

Mâts chinois
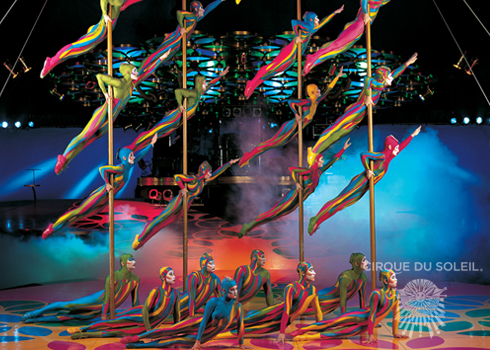
Un extrait du spectacle
site
Hyperréalité
Jeau Baudrillerd
« Jai cherché lAmérique sidérale, celle de la liberté vaine et absolue des freeways, jamais celle du social et de la culture celle de vitesse désertique, des motels et des surfaces minérales, jamais lAmérique profonde des murs et des mentalités. Jai cherché dans la vitesse du scénario, dans le réflexe indifférent de la télévision, dans le film des jours et des nuits à travers un espace vide, dans la succession merveilleusement sans affect des signes, des images, des actes rituels de la route, ce qui est le plus proche de lunivers nucléaire et énuclée qui est virtuellement le nôtre jusque dans les chaumières européennes.
Jai cherché la catastrophe future et révolue du social dans la géologie, dans ce retournement de la profondeur dont témoignent les espaces striés, les reliefs de sel et de pierre, les canyons où descend la rivière fossile, labîme immémorial de lenteur que sont lérosion et la géologie, jusque dans la verticalité des mégalopoles.
Cette forme nucléaire, cette catastrophe future, je savais tout cela à Paris. Mais pour le comprendre, il faut prendre la forme du voyage, qui dit Virilio réalise lesthétique de la disparition.
Car la forme désertique mentale grandit à vue dil, qui est la forme épurée de la désertion sociale. La désaffection trouve sa forme épurée dans le dénuement de la vitesse. Ce que lénucléation sociale a de froid et de mort retrouve ici, dans la chaleur du désert, sa forme contemplative. La transpolitique trouve là, dans la transversalité du désert, dans lironie de la géologie, son espace générique et mental. Linhumanité de notre monde ultérieur, asocial et superficiel, trouve demblée ici sa forme esthétique et sa forme extatique. Car le désert nest que cela : une critique extatique de la culture, une forme extatique de la disparition. »

BAUDRILLARD, Jean, Amérique, Paris, Grasset, 1986, p. 16-17.
La France perd son triple A
Dégradation de la note de la dette souvraine de la France par l'agence S&P.
demain, ouverture pour inventaire

A défaut d'un autre monde, un autre jour est possible.
demain, ouverture pour inventaire.
Quand les mots valent de lor

VERS LE CAPITALISME LINGUISTIQUE PAR FRÉDÉR I C KAPLAN *
LE SUCCÈS de Google tient en deux algorithmes : lun, qui permet de trouver des pages répondant à certains mots, la rendu populaire ; lautre, qui affecte à ces mots une valeur marchande, la rendu riche. La première de ces méthodes de calcul, élaborée par MM. Larry Page et Sergey Brin alors quils étaient encore étudiants en thèse à luniversité Stanford (Californie), consistait en une nouvelle définition de la pertinence dune page Web en réponse à une requête donnée. En 1998, les moteurs de recherche étaient certes déjà capables de répertorier les pages contenant le ou les mots demandés. Mais le classement se faisait souvent de façon naïve, en comptabilisant le nombre doccurrences de lexpression cherchée. Au fur et à mesure que la Toile sétendait, les résultats proposés aux internautes étaient de plus en plus confus. Les fondateurs de Google proposèrent de calculer la pertinence de chaque page à partir du nombre de liens hypertextes pointant vers elle un principe inspiré de celui qui assure depuis longtemps la reconnaissance des articles académiques. Plus le Web grandissait, plus lalgorithme de MM. Page et Brin affinait la précision de ses classements. Cette intuition fondamentale permit à Google de devenir, dès le début des années 2000, la première porte dentrée du Net.
Alors que bien des observateurs se demandaient comment la société californienne allait pouvoir monétiser ses services, cest linvention dun second algorithme qui a fait delle lune des entreprises les plus riches du monde. A loccasion de chaque recherche dinternaute, Google propose en effet plusieurs liens, associés à de courtes publicités textuelles, vers des sites dentreprises. Ces annonces sont présentées avant les résultats de la recherche proprement dits. Les annonceurs peuvent choisir les expressions ou mots-clés auxquels ils souhaiteraient voir leur publicité associée. Ils ne paient que lorsquun internaute clique effectivement sur le lien proposé pour accéder à leur site. Afin de choisir quelles publicités afficher pour une requête donnée, lalgorithme propose un système denchères en trois étapes :
Lenchère sur un mot-clé. Une entreprise choisit une expression ou un mot, comme « vacances », et définit le prix maximum quelle serait prête à payer si un internaute arrivait chez elle par ce biais. Pour aider les acheteurs de mots, Google fournit une estimation du montant de lenchère à proposer pour avoir de bonnes chances de figurer sur la première page de résultats. Les acheteurs peuvent limiter leur publicité à des dates ou à des lieux spécifiques. Mais attention : comme on va le constater, le fait davoir lenchère la plus haute ne garantit pas que vous serez le premier sur la page.
Le calcul du score de qualité de la publicité. Google attribue à chaque annonce, sur une échelle de un à dix, un score, en fonction de la pertinence de son texte au regard de la requête de lutilisateur, de la qualité de la page mise en avant (intérêt de son contenu et rapidité de chargement) et du nombre moyen de clics sur la publicité. Ce score mesure à quel point la publicité fonctionne, assurant à la fois de bons retours à lannonceur et dimposants revenus à Google, qui ne gagne de largent que si les internautes choisissent effectivement de cliquer sur le lien proposé. Lalgorithme exact qui établit ce score reste secret, et modifiable à loisir par Google.
Le calcul du rang. Lordre dans lequel les publicités apparaissent est déterminé par une formule relativement simple : le rang est lenchère multipliée par le score. Une publicité ayant un bon score peut ainsi compenser une enchère plus faible et arriver devant. Google optimise ici ses chances que linternaute clique sur les publicités proposées.
Ce jeu denchères est recalculé pour chaque requête de chaque utilisateur des millions de fois par seconde ! Ce second algorithme a rapporté à la firme de Mountain View la coquette somme de 9,72 milliards de dollars pour le troisième trimestre 2011 un chiffre en croissance de 33 % par rapport à la même période de lannée 2010 (1).
Le marché linguistique ainsi créé par Google est déjà global et multilingue. A ce titre, la Bourse des mots qui lui est associée donne une indication relativement juste des grands mouvements sémantiques mondiaux. La société propose dailleurs des outils simples et ludiques pour explorer une partie des données quelle collecte sur lévolution de la valeur des mots. Cest ainsi que nous pouvons voir comment les fluctuations du marché sont marquées par les changements de saison (les mots « ski » et « vêtements de montagne » ont plus de valeur en hiver, « bikini » et « crème solaire » en été). Les flux et les reflux de la valeur du mot « or » témoignent de la santé financière de la planète. Lentreprise gagne évidemment beaucoup dargent sur les mots pour lesquels la concurrence est forte (« amour », « sexe », « gratuit »), sur les noms de personnes célèbres (« Picasso », « Freud », « Jésus », « Dieu »), mais également dans des domaines de langue où la spéculation est moindre. Tout ce qui peut être nommé peut donner lieu à une enchère.
GOOGLE a réussi à étendre le domaine du capitalisme à la langue elle-même, à faire des mots une marchandise, à fonder un modèle commercial incroyablement profitable sur la spéculation linguistique. Lensemble de ses autres projets et innovations technologiques quil sagisse de gérer le courrier électronique de millions dusagers ou de numériser lensemble des livres jamais publiés sur la planète peuvent être analysés à travers ce prisme. Que craignent les acteurs du capitalisme linguistique ? Que la langue leur échappe, quelle se brise, se « dysorthographie », quelle devienne impossible à mettre en équations. Quand le moteur de recherche corrige à la volée un mot que vous avez mal orthographié, il ne fait pas que vous rendre service : le plus souvent, il transforme un matériau sans grande valeur (un mot mal orthographié) en une ressource économique directement rentable.
Quand Google prolonge une phrase que vous avez commencé à taper dans la case de recherche, il ne se borne pas à vous faire gagner du temps : il vous ramène dans le domaine de la langue quil exploite, vous invite à emprunter le chemin statistique tracé par les autres internautes. Les technologies du capitalisme linguistique poussent donc à la régularisation de la langue. Et plus nous ferons appel aux prothèses linguistiques, laissant les algorithmes corriger et prolonger nos propos, plus cette régularisation sera efficace.
Pas de théorie du complot : lentreprise nentend pas modifier la langue à dessein. La régularisation évoquée ici est simplement un effet de la logique de son modèle commercial. Pour réussir dans le monde du capitalisme linguistique, il faut cartographier la langue mieux que nimporte quel linguiste ne sait le faire aujourdhui. Là encore, Google a su construire une stratégie innovante en développant une intimité linguistique sans précédent avec ses utilisateurs. Nous nous exprimons chaque jour un peu plus au travers dune des interfaces de la société ; pas simplement lorsque nous faisons une recherche, mais aussi quand nous écrivons un courrier électronique avec Gmail ou un article avec Google Docs, quand nous signalons une information sur le réseau social Google +, et même oralement, à travers les interfaces de reconnaissance vocale que Google intègre à ses applications mobiles. Nous sommes des millions chaque jour à écrire et à parler par son biais. Cest pourquoi le modèle statistique multilingue quil affine en permanence et vers lequel il tente de ramener chaque requête est bien plus à jour que le dictionnaire publié annuellement par nos académiciens. Google suit les mouvements de la langue minute par minute, car il a le premier découvert en elle un minerai dune richesse extraordinaire, et sest doté des moyens nécessaires pour lexploiter.
La découverte de ce territoire du capitalisme jusquici ignoré ouvre un nouveau champ de bataille économique. Google bénéficie certes dune avance importante, mais des rivaux, ayant compris les règles de cette nouvelle compétition, finiront par se profiler. Des règles finalement assez simples : nous quittons une économie de lattention pour entrer dans une économie de lexpression. Lenjeu nest plus tant de capter les regards que de médiatiser la parole et lécrit. Les gagnants seront ceux qui auront pu développer des relations linguistiques intimes et durables avec un grand nombre dutilisateurs, pour modéliser et infléchir la langue, créer un marché linguistique contrôlé et organiser la spéculation sur les mots. Lutilisation du langage est désormais lobjet de toutes les convoitises. Nul doute quil ne faudra que peu de temps avant que la langue elle-même sen trouve transformée.
(1) « Google Q3 2011: $9.72 billion in revenue, $2.73 billion in net income », http://techcrunch.com, 13 octobre 2011.
* Chercheur à lEcole polytechnique fédérale de Lausanne, auteur de La Métamorphose des objets, FYP Editions, Limoges, 2009, et, avec Georges Chapouthier, de LHomme, lAnimal et la Machine, CNRS Editions, Paris, 2011.
A LOMBRE DE SIDI LFALUS ET LALLA LFLOUSS
suivi de L'INFORMATIQUE DANS LES NUAGES
La feuille est-elle l'arbre ?
L'arbre est-il la forêt ?
Osons la question folle : la bite est-elle le phallus ?

Oui tant que la fécondité était la figure symbolique représentée mais plus du tout quand c'est la virilité. Cette Transposition destinée à faire fonctionner le phallus comme l'emblème d'une fausse coexistence pacifique entre mâle et femelle, qui symbolise l'utopie de parvenir à ne faire plus qu'UN dans le "rapport sexuel"

Faudrait peut-être réapprendre à se servir
de sa tête avant qu'elle ne soit coupée !
Démonstration mathématique
1 - Arbre et forêt
Voici deux classes définissant les arbres n-aires
class Tree { // Arbres n-aires int node ; Forest children ; Tree (int node, Forest children) { this.node = node ; this.children = children ; } } class Forest { // Une liste de Tree Tree first ; Forest next ; Forest (Tree first, Forest next) { this.first = first ; this.next = next ; } }
Une forêt est donc une liste ordonnée d'arbres. Dans un arbre, l'ordre gauche-droit des sous-arbres compte, il compte aussi dans une forêt. Enfin la racine de chaque arbre est identifiée par un entier, dans le champ node.
La définition des arbres est inductive, on pourrait aussi l'écrire ainsi :
T ::= (n,F) n un entier
F ::= є forêt vide
∣ (T, F)
(En supposant en outre que tous les entiers n sont distincts.)
1. Y-a-t-il des arbres, des forêts, vides ? Quelles sont les conséquences pour la programmation en Java ? Et sur lavenir du Maroc ?
2. Définir inductivement l'ordre postfixe des sommets d'une forêt, qui place les descendants avant les ancêtres et les sommets des arbres d'une forêt de gauche à droite. On cherchera à définir inductivement une suite ordonnée de sommets, à partir des définitions des arbres et des forêts.
3. Écrire deux méthodes postOrder, une pour les forêts l'autre pour les arbres, qui renvoient une liste des sommets dans l'ordre postfixe (à l'aide de notre amie la classe des listes enrichie comme bon nous semble).
Solution
2 Forêt profonde
Tree dfsTree(int node, boolean [] vu) { return new Tree(node, dfsForest(succ[node], vu)) ; } Forest dfsForest(List nodes, boolean [] vu) { if (nodes == null) return null ; int node = nodes.val ; if (!vu[node]) { vu[node] = true ; Tree t = dfsTree(node, vu) ; Forest f = dfsForest(nodes.next, vu) ; return new Forest (t, f) ; } else return dfsForest(nodes.next, vu) ; } Forest dfs(List nodes) { boolean [] vu = new boolean [succ.length] ; return dfsForest(nodes, vu) ; } Forest dff() { List allNodes = null ; for (int i = succ.length-1 ; i >= 0 ; i--) allNodes = new List (i, allNodes) ; return dfs(allNodes) ; }
CQFD